Gestern fand beim Schützenverein „Frohsinn“ in Leupoldsgrün das 22. Muckturnier der JU Leupoldsgrün statt. Zum Schnapszahl-Jubiläum gab es auch gleich noch einen neuen Rekord: Das Turnier war zum ersten Mal bereits im Vorfeld bis auf den letzten Platz ausgebucht. Die 50. Voranmeldung ging schon fast eine Woche vorher, am 08.02., ein und machte die maximal 100 Teilnehmer voll. Leute, ihr seid einfach der Wahnsinn :-) Das soll erstmal einer der JU nachmachen – ein Muckturnier mit dieser Stetigkeit über so viele Jahre derart erfolgreich durchzuziehen. Chapeau.
Das Turnier lief, natürlich auch dank dem Muckturnier-Programm, wieder vollkommen reibungslos ab. 50 Paare anmelden? Schüttelt man dank Voranmeldungen mit Anmeldungs-Codes in 20 Minuten aus dem Ärmel. Auslosung? Direkt geschenkt dazu. Fünf nach Sieben ging’s los. Zeitlicher Ablauf? Dank Turnier-Zeitplan planbar und mit ein paar Minuten Abweichung exakt wie vorgesehen. So läuft es, wenn Profis (die JU) mit Profi-Werkzeug (dem Muckturnier-Programm) arbeiten.
Der von der JU selber und Sascha Gries gesponsorte Hauptpreis, ein Rundflug für das Gewinner-Team, ging in diesem Jahr an altgediente Muckturnier-Teilnehmer: Philipp Knoch und Matthias Wonsack. Nochmals herzlichen Glückwunsch und viel Spaß!
In der kompletten Rangliste kann jeder nochmal seine Platzierung nachsehen.
Möglich wird das Ganze natürlich, wie jedes Jahr, erst durch die großzügigen Sponsoren. Das waren dieses Mal (in alphabetischer Reihenfolge, unabhängig vom Wert des Preises):
ASV Leupoldsgrün
Bäckerei Bayreuther (Selbitz)
Berres Nudelshop (Leupoldsgrün)
Brauerei Meinel (Hof)
Christine Cziep - So schön (Leupoldsgrün)
CSU-Fan-Shop (München)
Degel Landtechnik (Leupoldsgrün)
Dorfladen Onkel Emil (Leupoldsgrün)
Ellis Wunderland (Konradsreuth)
Fa. Sell (Helmbrechts)
Fa. Sommer Fassadensysteme (Döhlau)
Frankonia Hydraulik GmbH (Wolframs-Eschenbach)
Friseur Hamada (Hof)
Gasthaus Gebhardt (Ahornberg)
Gasthaus Sack (Ahornberg)
Gasthof Puchta (Wölbattendorf)
Getränke Hofmann (Helmbrechts)
Haarschneiderei Leupoldsgrün
Hair Fashion by Selma (Konradsreuth)
Hofladen Leupold (Volkmannsgrün)
Hofrichter Betonwerk (Stegenwaldhaus)
Imkerei Christian Lange (Leupoldsgrün)
Jahn-Orthopädie (Hof)
Klick-Apotheke (Selbitz)
Lead Intelligence Equipment GmbH (Naila)
Löwen-Apotheke (Selbitz)
Marsmann Gewürze (Schauenstein)
Metzgerei Bloß (Schauenstein)
Metzgerei Günther (Schauenstein)
Metzgerei Herpich (Hof)
Metzgerei Kraft (Konradsreuth)
Metzgerei Lochner (Konradsreuth)
Metzgerei Strobel (Dörnthal)
Minges Kaffeerösterei GmbH (Breitengüßbach)
Müllers Hoflädla (Konradsreuth)
Münzer Sanitär (Schauenstein)
Orient Pizza Express (Helmbrechts)
Packwa Dekorationsideen (Hof)
Rolf Weber Gruppe (Schauenstein)
Saale-Apotheke (Schwarzenbach)
Schiller Fleisch (Hof)
Schützenverein „Frohsinn“ Leupoldsgrün
Sport Strobel (Schauenstein)
Sprudelkiste / Gasthaus Löhner (Leupoldsgrün)
Stadtwerke Hof
Willy Maisel GmbH (Konradsreuth)
Vielen, vielen Dank an euch alle, ohne euch wäre so ein Turnier nicht möglich!
Anmeldungscodes werden ab dem nächsten Release (4.0.0, t. b. a.) vernünftig abgesichert sein. Ja, kein Mensch will einen Anmeldungscode fälschen. Nein, das ist auch noch nie vorgekommen. Aber es geht hier ja nicht um „für ein Hobbyprojekt reicht’s schon“ oder „funktioniert doch“ – es geht darum, vernünftige Code-Qualität und eine vernünftige, professionelle Implementierung vorzulegen. Das gebietet die Programmierer-Ehre. Soll ja keiner sagen können, ich würde schlechten Code schreiben :-P
Was wir hatten, und warum das schlecht war
Ich dachte mir damals folgendes: Es braucht, zusätzlich zur eigentlichen Datenübertragung, einen Sicherheitsmechanismus. Weil sonst ist ein Muckturnier ausgebucht, und einer kommt auf die Idee, sich die Spezifikation anzuschauen (die ist einfach), und sich seinen eigenen Anmeldungscode zu bauen (auch das ist einfach). Und dann steht jemand da, und behauptet, er wäre ja vorangemeldet gewesen – obwohl das nicht stimmt. Oder – und sowas würde ich persönlich machen: Bauen wir einfach mal so einen Code, nur, um den Entwickler zu ärgen, bzw. ihm vor Augen zu führen, dass sein Kram nichts taugt.
Also: Wie machen wir das, einfach, und mit wenig Zeichen (damit die QR-Codes kompakt bleiben)? Augenscheinlich braucht es einen kryptographischen Hash, eine Prüfsumme der Nachricht. Für die Netzwerkfunktionalität nutze ich intern MD5. Da geht es zwar nicht um Sicherheit, sondern einfach nur darum, dass alle Clients auf demselben Stand sind – aber dann nehmen wir halt das. MD5 ist schnell und leicht zu berechnen, und der Hash ist vor allem kurz. Wichtig, weil die QR-Codes sollen ja kompakt bleiben. Also nehmen wir einfach einen geheimen Schlüssel und berechnen den MD5-Hash aus dem Schlüssel und dem Nachrichtentext, und hängen den Hash an die Nachricht an.
Ja, ich wusste auch zu dem Zeitpunkt bereits, das MD5 in einem kryptographischen Kontext schon lang gebrochen wurde, aber für so kurze Nachrichten und für den Zweck wird’s schon reichen. Oder?!
Warum war das ein Trugschluss bzw. eine schlechte Idee?
MD5 gilt seit vielen Jahren als nicht kollisionssicher. Angreifer können gezielt zwei verschiedene Nachrichten mit demselben Hash erzeugen. Das wusste ich wie gesagt schon, aber ich dachte, für so kurze Nachrichten wie ein Anmeldungs-Datagram wäre das irrelevant.
MD5 ist anfällig für sog. Length-Extension-Angriffe. Wenn ein Angreifer MD5(Schlüssel + Nachricht) kennt, kann er, ohne den Schlüssel zu kennen, einen gültigen Hash für (Schlüssel + Nachricht + zusätzliche Daten) berechnen.
Da der bisherige MD5-Hash nicht aus dem gesamten Datagram berechnet wurde, sondern nur aus Schlüssel, Turniername und Paar/Spielername (vor der Serialisierung, ohne den Header mit den Längenangaben), hätte man tatsächlich ohne großen Aufwand aus einem generierten Anmeldungscode einen anderen als gültig validierten berechen können, ohne den geheimen Schlüssel zu kennen. Das ist katastrophal!
In der Sicherheitsinformatik gilt das eherne Gesetz Never roll your own crypto – aber genau das habe ich mit meiner unreflektierten, selbergestrickten Lösung gemacht (Asche auf mein Haupt!).
HMAC basieren ebenfalls auf einer Hash-Funktion, das Verfahren behebt aber das Problem der potenziellen Anfälligkeit für einen Length-Extension-Angriff. Der geheime Schlüssel wird bei dem Verfahren zweistufig mit dem Nachrichtentext verwoben: Zunächst wird der Schlüssel mit einem „inneren Pad“ vermischt, dann wird das Ergebnis zusammen mit der Nachricht gehasht. Dann wird der Schlüssel mit einem „äußeren Pad“ vermischt, und das Ergbnis wird dann mit dem Ergbnis des ersten Hash-Vorgangs erneut gehasht. Das mutet erwas umständlich an, sorgt aber dafür, dass mit diesem Verfahren selbst eine an sich unsichere Hash-Funktion wie MD5 auch Stand jetzt noch sicher angewendet werden könnte.
Aber wenn wir es schon anders machen, dann machen wir es gleich „richtig“ richtig. Die jetzt benutzte HMAC-Hash-Funktion ist SHA-256. Der resultierende Hash von SHA-256 ist allerdings erheblich länger, als der von MD5. Beispiel: Die hexadezimale Repräsentation des MD5-Hashs von „Muckturnier.org“ ist 91765900c6885d64ef95987f05123140. Berechnet man den Hash mit SHA-256, ist das Resultat b4d08106b5b663dc4b4d18275fe8fcdb26e46abd3ab0ca27621ddcc7f9875579. Jetzt sollen ja aber die QR-Codes kompakt bleiben.
Netterweise kann man den Hash einfach abschneiden, indem man nur die ersten paar Bytes benutzt („Truncation“) – und das Ergebnis ist, vorausgesetzt, man benutzt genügend Bytes, immer noch kryptographisch sicher. Zum Einsatz kommen die ersten 16 Bytes – das ist dieselbe Länge, die der MD5-Hash vorher auch hatte. Das sind 128 Bits eines SHA-256-Hashs – und damit sprechen wir hier nicht von einem Kompromiss, sondern von Enterprise-Level Security.
Weiterhin wird per Standard jetzt kein zufälliger Sicherheitsschlüssel aus einer Untergruppe von ASCII-Zeichen mehr generiert, sondern 32 kryptographisch sicher zufällig generierte Bytes (irgendwann erkennt man mal den Unterschied zwischen Strings und Byte Arrays, was das eine und was das andere ist, und wann man was davon benutzt ;-) Das führt dazu, dass der Sicherheitsschlüssel (der jetzt auch nur noch auf explizite Anfrage nach einer Warnung geändert werden kann) 256 Bits an kryptograpsch sicherer Entropie darstellt – und das ist ein astronomisch großer Wert, der noch nicht einmal rein theoretisch gebrochen werden kann. Auch nicht mit Quantencomputern.
Wie Anmeldungscodes jetzt funktionieren
Die Spezifikation des Protokolls für Anmeldungscodes war von vornherein gut designt. Die Struktur ist exakt gleich geblieben. Nur kommen jetzt statt eines „nackten“ MD5-Hashs der Eingabedaten zur Absicherung die ersten 16 Bytes eines HMAC-SHA-256-Hashs des gesamten kodierten Datagrams zum Einsatz, unter Verwendung eines extrem sicheren Schlüssels. Besagter Schlüssel wird nach wie vor für jedes Turnier neu generiert und kommt nur ein Mal zum Einsatz.
Damit ist das Sicherheitskonzept der Anmeldungscodes jetzt keine undurchdachte „Wird schon passen dafür“-Lösung, sondern – auf absehbare Zeit – wirklich kryptographisch sicher. Das würde in dieser Form jetzt auch einem kryptographischen Audit standhalten. Und das, obwohl die Codes von der Struktur her genauso aussehen, wie bisher.
Das neue Protokoll ist nicht abwärtskompatibel
Es gibt zwei substanzielle Änderungen:
Die Hash-Funktion zum Generieren der Prüfsummen wurde geändert
Der Sicherheitsschlüssel wird jetzt nicht mehr direkt als Zeichenkette (String) gespeichert, sondern als Base64-Repräsentation von Binärdaten (Byte Array). Das ist deswegen notwendig, weil er ja nicht mehr aus druckbaren Zeichen besteht, sondern aus vollkommen zufälligen Bytes.
Bedingt dadurch ist das neue Anmeldungs-Code-Protokoll nicht abwärtskompatibel. Selbst, wenn man einen bereits gespeicherten Sicherheitsschlüssel in seine Base64-Darstellung konvertieren würde, könnten vorher erstellte Anmeldungscodes nicht verarbeitet werden, da sich ja die Hash-Funktion geändert hat. Das Einführen einer Kompatibilitätsschicht (also das weitere Unterstützen von Anmeldungscodes, die mit Protokollversion 2 erzeugt wurden) erscheint mir nicht sinnvoll, da die Codes ja nur für dieses eine Turnier genutzt werden. Später tauchen ja keine alten Codes mehr auf.
Also bitte beachten: Wenn bereits Anmeldungscodes generiert wurden, dann das Turnier auch mit der bisherigen Version des Programms auswerten, und erst hinterher updaten. Darauf wird aber im Release Announcement nochmal hingewiesen.
Da haben wir ja gerade nochmal die Kurve gekriegt ;-)
In Version 3.11.0 wurde das Konzept für den Auslosungsmodus und die automatische Paar- bzw. Tischauswahl überarbeitet. Außerdem gibt es Usability-Verbesserungen – und natürlich auch einige Bugfixes.
Bessere Auslosung ganzer Runden
Beim Auslosen ganzer Runden wird jetzt – sofern das aktiviert ist – das Zulosen bisheriger Gegner bzw. Partner erheblich besser vermieden, als bisher. Ausführlich wurde das bereits im Tech-Preview Bessere Auslosung für ganze Runden beschrieben. In Version 3.11.0 wurde es genau so umgesetzt.
Besseres Turnierdatenbank-Datei-Management
Es ist jetzt möglich, beim Starten automatisch die letzte geöffnete Turnierdatenbank zu laden. Das ist insbesondere dann praktisch, wenn man Voranmeldungen für ein Turnier entgegennimmt, da diese ja typischerweise über einige Tage verteilt kommen – man also das Programm viele Male starten muss. Jetzt kann man einfach das Programm öffen, und die letzte Datenbank ist da (sofern sie nicht geschlossen, verschoben, gelöscht etc. wurde).
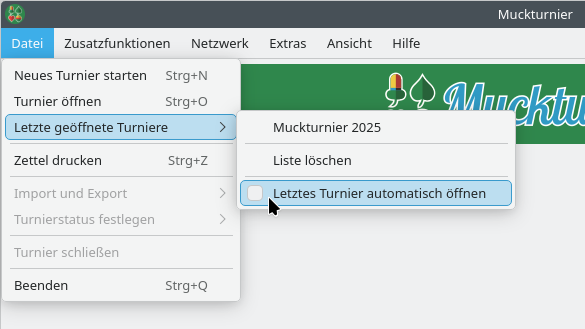
Weiterhin werden jetzt die letzten fünf geöffneten Turnierdatenbanken gespeichert und können direkt aufgerufen werden.
Zu finden sind beide Funktionen im neuen Menüpunkt „Datei“ → „Letzte geöffnete Turniere“:
Abgesehen davon gibt es jetzt nicht mehr nur die Option, als Startverzeichnis für das Öffnen von bestehenden Turnierdatenbanken bzw. dem Erstellen neuer das Verzeichnis der zuletzt benutzen Datenbank zu verwenden. Als zusätzliche Optionen kann man nun auch das Standard-„Dokumente“-Verzeichnis oder ein beliebiges anderes wählen.
Eingestellt werden kann das Start-Verzeichnis im Einstellungen-Dialog auf der „Verzeichnisse“-Seite. Diese enthält jetzt auch den Standard-Verzeichnisnamen für den Export von Anmeldungscodes, der vorher eine eigene Seite hatte.
Auslosung und die automatische Auswahl
Seit Version 3.8.0 ist der Auslosungsmodus in die immer sichtbaren Einstellungen beim Erstellen eines neuen Turniers gewandert. Weiterhin konnte der Auslosungsmodus sowohl auf der Anmeldungs- als auch auf der Ergebnisse-Seite geändert werden – einmal benannt aus Sicht der Auslosung und einmal aus Sicht der Ergebniseingabe.
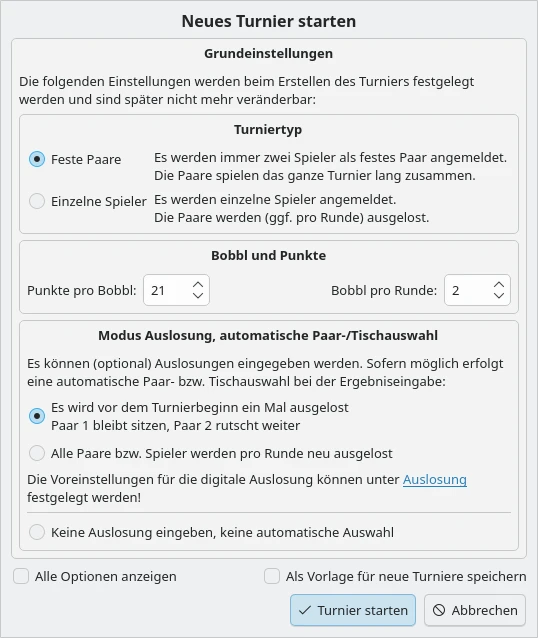
Objektiv betrachtet ist die Möglichkeit, den Auslosungsmodus an drei Stellen konfigurieren zu können – auch während des Turniers – übers Ziel hinausgeschossen. Letztlich sieht es doch so aus: Wenn ich eine Auslosung eingebe, dann möchte ich auch eine entsprechende automatische Paar- bzw. Tischauswahl haben. Ich gebe die Auslosung ja nicht aus Spaß ein. Und: Es steht vor dem Turnier fest, ob ich pro Runde auslose, nur die 1. Runde auslose und dann die Paare 2 weiterrutschen lasse, oder ob ich jede Runde Zettel ziehen lasse (die Auslosung also bis zur Ergebniseingabe nicht kenne) und somit überhaupt keine Auslosung eingebe. Und das ändert sich während des Turniers auch nicht.
Folgerichtig gehört der Auslosungs- und Auswahlmodus in die fixen Einstellungen, die beim Erstellen der Datenbank festgelegt und während des Turniers nicht mehr geändert werden können. Und das ist jetzt der Fall. Der „Neues Turnier starten“-Dialog sieht jetzt so aus:
Das vereinfacht die Bedienung, die Oberfläche und den Code – und sorgt für weniger Verwirrung. In einem „Paar 1 bleibt sitzen, Paar 2 rutscht weiter“-Turnier bekommt man jetzt z. B. nicht mehr die Warnung, dass Auslosungen ab Runde 2 ignoriert werden – man kann einfach gleich von vornherein nur eine einzige Auslosung eingeben.
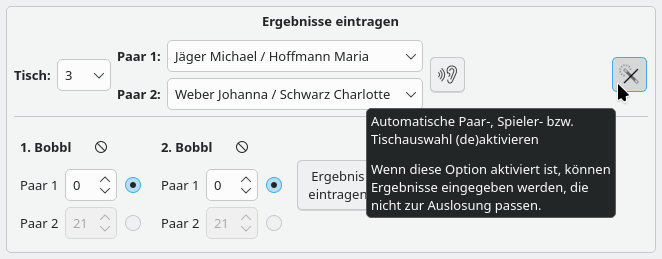
Selbstverständlich ist es natürlich nach wie vor möglich, bei der Ergebniseingabe von der Auslosung abzuweichen, egal welcher Modus eingestellt wurde. Das geht wie gehabt, indem man den „Automatische Paar- Spieler- bzw. Tischauswahl (de)aktivieren“-Knopf aktiviert:
Da der Auswahlmodus im laufenden Betrieb nicht mehr umgeschaltet werden kann, könnte theoretisch nun folgendes Problem mit alten Datenbanken auftreten: Womöglich wurde der Modus auf „keine automatische Auswahl“ gesetzt, obwohl mehrere Runden ausgelost wurden. In dem Fall wären diese dann nicht mehr einsehbar. Für diesen Spezialfall gibt es unter „Extras“ → „Datenbank“ → „Auslosungsmodus ändern“ trotzdem die Möglichkeit, die Einstellung im Nachhinein anzupassen. Nur für den Fall der Fälle.
Farben für Markierungen
Tatsächlich ist es gar nicht so einfach, Farben für Markierungen zu finden, die sich 1. gut voneinander unterscheiden lassen, 2. sowohl auf einem hellen als auch auf einem dunklen Hintergrund gut zu lesen sind – und das 3. sowohl auf dem normalen als auch auf dem alternativen Zeilen-Hintergund. Deswegen schlägt das Programm jetzt beim Erstellen von Markierungen eine Farbe vor, die alle Kriterien erfüllt.
Folgende acht Farben sind jetzt definiert, und werden von oben nach unten voreingestellt, sofern sie noch nicht benutzt wurden:
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Text
Mehr Markierungen werden vermutlich nicht unbedingt gebraucht werden. Natürlich kann aber die Farbe nach wie vor auch frei gewählt werden.
Bei der Farbauswahl wird jetzt weiterhin der visuell beurteilte Farbabstand nach CIEDE2000 zu allen bestehenden Markierungsfarben berechnet und ggf. bei zu großer Ähnlichkeit eine Warnung angezeigt.
Zeitanzeige des Turnierzeitplans überarbeitet
Bisher wurde auf der Turnierzeitplan-Seite intern millisekundengenau gerechnet. Das hatte zur Folge, dass es unter Umständen zu merkwürdigen Zeitanzeigen oder Warnungen kam, je nach dem, wann genau eine Runde gestartet wurde. So konnte es z. B. passieren, dass zwei Mal hintereinander dieselbe Sekunde angezeigt wurde, und dann ein Zwei-Sekunden-Sprung kam, oder eine Warnung wie „Bis zum Start der nächsten Runde fehlen noch 0 Minuten, soll wirklich schon gestartet werden?“ angezeigt wurde.
Jetzt werden jetzt die Abweichungen zwischen Soll- und Ist-Start bzw. -Ende nur noch minutengenau berechnet. Damit gibt es jetzt keine Rundungsdifferenzen bei den Abweichungen mehr, die bisher teilweise durch die sekundengenaue Berechnung vorkamen. Alle Zeitanzeigen werden jetzt nur noch sekundengenau berechnet, ohne Berücksichtigung von Millisekunden.
Damit sollten jetzt merkwürde Anzeigen und Meldungen der Vergangenheit angehören.
Weitere Neuerungen
Der Export einer Paar- bzw. Spielerliste ist jetzt nicht mehr nur als Export in eine Datei möglich, die Liste kann jetzt auch in die Zwischenablage kopiert werden (eine Anmeldung pro Zeile). Weiterhin kann der Dialog jetzt auch im Netzwerkbetrieb aufgerufen werden (Netzwerkänderungen nach dem Öffnen werden allerdings nicht berücksichtigt).
Es ist jetzt möglich, die Einstellungen für das Zeitanzeige-Display in eine Datei zu exportieren und sie aus einer solchen Datei wieder zu importieren. Damit können jetzt die Einstellungen einfach auf einen anderen Computer zu übertragen bzw. für später gesichert werden.
Es kann jetzt ein Standardverzeichnisname für das Speichern von Anmeldungscodes definiert werden. Wenn es noch nicht existiert, wird das entsprechende Verzeichnis automatisch in dem Verzeichnis erstellt, in dem die Turnierdatenbank gespeichert wurde. Das Zielverzeichnis für den Export von Anmeldungscodes wird automatisch auf dieses Verzeichnis voreingestellt.
Wenn es offene Runden gibt, und es wurden Ergebnisse eingegeben, die nicht zur Auslosung passen, dann sind ggf. Warnungen über Kollisionen nicht richtig, bzw. Kollisionen können nicht korrekt vermieden werden (da nicht klar ist, wer noch gegen wen spielen wird). Wird in diesem Zustand ausgelost, dann wird jetzt eine entsprechende Warnung angezeigt.
Behobene Fehler (Auswahl)
Beim Wechseln zwischen verschiedenen Zeitanzeige-Display-Einstellungen werden jetzt die Farben der einzelnen Texte korrekt gesetzt.
Beim Laden bzw. Importieren von Zeitanzeige-Display-Einstellungen werden jetzt nicht gesetzte Hintergrundbilder korrekt angezeigt (ggf. vorher gesetzte Bilder werden entfernt).
Wenn das Zeitanzeige-Display nicht durch das Klicken auf das X des Fenster-Managers geschlossen wird, sondern durch das Drücken der Escape-Taste wird jetzt auch in diesem Fall gefragt, ob ggf. geänderte Einstellungen gespeichert werden sollen.
Der „Einstellungen“-Menüknopf auf der Anmeldungsseite enthält jetzt einen Eintrag zum (De-)Aktivieren der phonetischen Suche. Die Einstellung wird auch angewandt, wenn man den Namen einer Anmeldung editiert – aber nach dem Start des Turniers gab es bisher keine Möglichkeit mehr, sie zu ändern (da der Knopf dann ausgeblendet wird).
Beim Import einer Paar- bzw. Spielerliste konnte es unter Umständen vorkommen, dass als potenzielle Duplikate eingestufte Einträge doppelt importiert wurden. Das führte dazu, dass es mehrere Anmeldungen mit exakt demselben Namen gab (und das darf nicht passieren!). Der Import-Dialog wurde jetzt überarbeitet – nun sollte das nicht mehr passieren.
Es ist jetzt nicht mehr möglich, mit einem Dateiexport die gerade geöffnete Datenbank zu überschreiben.
Die vollständige Liste aller Änderungen enthält wie immer der ChangeLog.
Immer mal wieder gibt es auf Muckturnieren Nachfragen, wie man die Spielstände aufschreiben muss. Oder man bekommt Zettel, wo die Spielstände verkehrt aufgeschrieben wurden – trotz aller Sorgfalt beim Design der Vorlagen. Und das führt dann mitunter zu Verwirrung. Deswegen möchte ich hier mal was über Spielstandzettel schreiben.
Aufschreiben eines Muckers
Bis vor ein paar Jahren war mir nur eine Variante des Aufschreibens bekannt: Paar 1 steht oben, Paar 2 steht unten, und man schreibt die Bobbl von links nach rechts auf. War mir auch irgendwie klar, schließlich schreibt man doch so die Ergebnisse einer Muckrunde auf, oder?!
Hier ein Beispiel für einen Spielstandzettel eines „normalen“ Muckers, außerhalb eines Muckturniers (die Datei habe ich vor ein paar Jahren mal auf Wikipedia hochgeladen):
Paar 1, repräsentiert durch die Römisch-I oben (Schreiber ist I), Paar 2 als Römisch-II unten und die Bobbl von links nach rechts. Ich persönlich habe noch bei keinem Karter mitgekartet, wo anders aufgeschrieben wurde.
Ähnlich sahen auch schon immer die Spielstandzettel auf den Muckturnieren aus, auf denen ich war, hier ein Beispiel eines alten Zettels des Muckturniers der JU Leupoldsgrün:
Den habe ich auch vor Jahren bei Wikipedia hochgeladen. Die Bobbl wurden damals noch als „Spiel“ bezeichnet; mittlerweile konnte sich erfreulicherweise die korrekte Bezeichnung „Bobbl“ etablieren; ein „Spiel“ bezeichnet korrekterweise ein eben solches innerhalb eines Bobbls, z. B. einen Wenz.
Was ist der sinnvollere Spielstandzettel?
Für das Programm wurde die Eingabemaske für die Spielstände – sinnvollerweise – genau wie das Layout der Spielstandzettel entworfen. Viel später hatte ich meinen ersten Kontakt mit Spielstandzetteln, bei denen die Bobbl nicht von links nach rechts, sondern von oben nach unten aufgeschrieben werden. Seit Muckturnier 4.3.0 gibt es zwei Optionen für die Spielstandeingabe: Eine „horizontale“ und eine „vertikale“ Variante. Aber welche sind sinnvoller?
Für die „horizontale“ Variante sprechen meiner Meinung nach zwei Argumente:
Man schreibt einen normalen Mucker auch so auf. Das entspricht dem, was man außerhalb eines Turniers auch tut. Wieso sollte man es auf einem Muckturnier anders machen als sonst?
Die Eingabe von „horizontalen“ Spielstandzetteln ist programmseitig übersichtlicher und die Anzeige der Ergebnisse braucht jeweils eine Zeile weniger.
Am besten sieht man es an einem Beispiel. Hier benutzt wurde Version 3.10.0.
Hier die „normale“ (also „horizontale“) Variante:
Und hier dasselbe als „vertikale“ Variante:
Der Workflow der „horizontalen“ Variante ist m. E. einleuchtender und gefälliger. Und ein definitiv objektivierbarer Vorteil dieser Variante ist, dass die Ergebnisse mit jeweils einer Zeile weniger an Platzbedarf und auch übersichtlicher dargestellt werden können.
Fazit
In Anbetracht der gängigen Gepflogenheiten beim Aufschreiben eines normalen Muckers und auch aus Sicht der Umsetzung der Eingabemaske im Muckturnier-Programm und deren Bedienung empfehle ich ganz klar das Verwenden von „horizontalen“ Spielstandzetteln.
Ungeachtet dessen bringt das Programm die Auswahlmöglichkeit zwischen „horizontal“ und „vertikal“ mit – sowohl bei den Vorlagen zum Erstellen von Spielstandblöcken, als auch für die Ergebnis-Eingabemaske. Letztlich kann also jeder selbst entscheiden, welche Variante zum Einsatz kommen soll. Man sollte nur definitiv darauf achten, dass jedem klar ist, wie aufgeschrieben wird, und die Eingabemaske entsprechend der Spielstandzettel-Variante eingestellt wird.




#/media/Datei:Spielstandzettel_Muckrunde.jpg){kind=link}
#/media/Datei:Spielstandzettel_Muckturnier.jpg){kind=link}